- Dates: April 20-24 (Mon-Fri), 2015.
- Venue: Athens, Greece
- Host: Yannis Smaragdakis
Venue
The meeting will take place at the University of Athens Club (Kostis Palamas building). The venue is in downtown Athens, within a short walking distance of the Syntagma square (the modern center of town). The building offers an array of options for internet access (guest access to the University network, eduroam) and a dining area for lunch. An all-day coffee and pastries buffet will be available throughout. Since laptop use during the meeting is discouraged, there will be a designated time period every day for laptop-detox (e.g., catching up and responding to urgent emails).Accommodation
There is an abundance of hotels in the area, at all price ranges. You should prefer the areas south of the meeting venue, where most of the hotels are anyway. See the attached map for the recommended area of your hotel search. Location-wise, you will be well-served by any of the ~100 hotels in the shown map area. Even the furthest away hotels on this map are within a half hour walk, or, equivalently, a 2-stop metro ride. Sample picks:- Central Hotel (21 Apollonos St.): mid-range, good location for tourist areas, 1km to meeting venue.
- Amalia Hotel (10 Amalias Ave.): mid-range+, very central, next to Syntagma Square, quite close to meeting venue (<1km).
- Divani Caravel (2 Vas. Alexandrou Ave.): mid-high range, a reliably high-quality Athens hotel, 2km to meeting venue.
- Titania Hotel (52 Panepistimiou Ave. not in the map area): well-known 4-star hotel, very close to meeting venue (0.5km).
- Grande Bretagne (Syntagma square): the top luxury hotel in downtown Athens, for those wanting to splurge. <1km to meeting venue.
Registration
Registration is required, however fees will be collected at the meeting. Please register by emailing Dimitris Galipos: dgalipos@di.uoa.gr. Dimitris is in charge of all the meeting logistics. The registration fee for the meeting is 180euros, which includes the cost for the all-day coffee buffet and lunch buffet for 5 days, as well as the cost of an excursion to the Acropolis. Dinners are not included--although we expect a planned group outing for dinner every evening, pricing and payment arrangements will be made on the spot.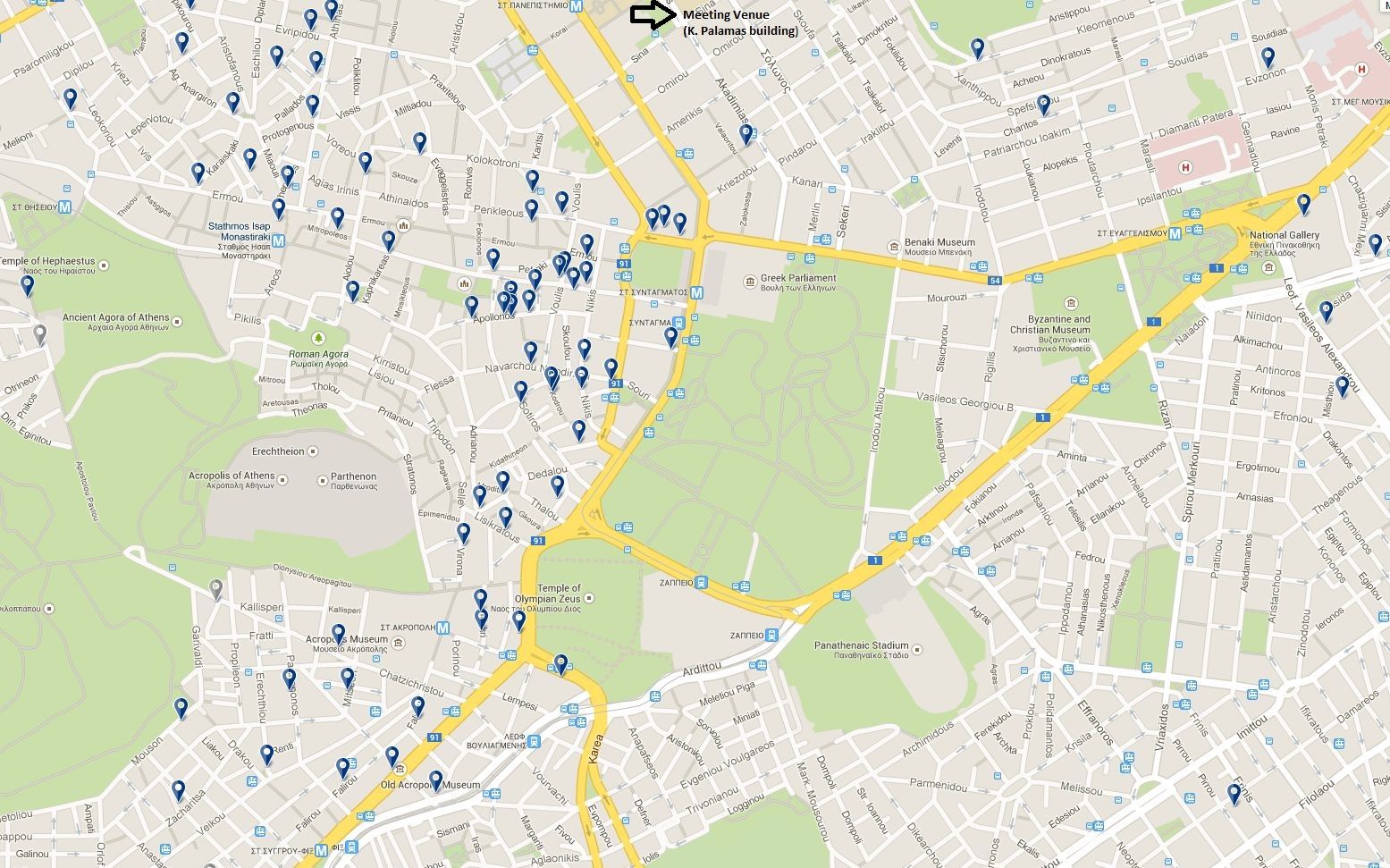
Registered
- Gilad Bracha
- Edwin Brady
- James Cheney
- Adam Chlipala
- Jonathan Edwards
- Matthew Flatt
- Georgios Fourtounis
- Stefan Hanenberg
- Roberto Ierusalimschy
- Daan Leijen
- Jan-Willem Maessen
- Sean McDirmid
- Mark Miller
- James Noble
- Klaus Ostermann
- Nikolaos Papaspyrou
- Roly Perera
- Panagiotis Rondogiannis
- Kostis Sagonas
- Francisco Sant'anna
- Yannis Smaragdakis
- Ross Tate
- Sam Tobin Hochstadt
- Andrew Tolmach
- Tijs van der Storm
- Cristina Videira Lopes
Monday
Sean McDermid: Going Against the Flow for Type-less Programming
Object-oriented languages are plagued by poor support for type inference given difficulty in combining subtype and parametric polymorphism. This talk will introduce a Type-less type system that provides useful type feedback about OO code with less type annotations. Type-less rethinks type checking as a modular field-aware value flow analysis to allow inference on assignment with simplified variance and binding. Type-less also does type inference backwards to specializes term types based on their usage rather than generalizing types to validate their usage. Type annotations are then unnecessary in client code that does not define new abstractions, and greatly reduced otherwise. The result is a fluid programming experience whose feel approaches that of a dynamic language, which I will demo, of course!Adam Chlipala: The Ur/Web People Organizer: A Library for Rapid Development of Web Apps from Components
I'll introduce a new library for the Ur/Web programming language that I talked about at past meetings of this group. Ur/Web has some novel features that support unusual and effective styles of encapsulation; I'll review those a bit. The purpose of the talk, which will focus heavily on code demos, is the new library, the Ur/Web People Organizer, which is based on a component architecture that allows very rapid assembly of applications for running meetings, etc. A growing set of components encapsulate such ideas as scheduling meetings between two groups of people, taking RSVPs for different subevents, etc. Each component has a rich static type, expressing its polymorphic dependencies on the schemas of selected SQL database tables.Markus Völter: Experiences from building mbeddr
Over the last four years a team at fortiss and itemis have built mbeddr, an extensible set of integrated languages for embedded software development. mbeddr relies on the JetBrains? MPS language workbench. MPS' projectional editor enables wide-ranging language modularity and flexible notations that include text, prose, tables, mathematics and diagrams. As far as we know, mbeddr is the largest and most sophisticated system built on top of a projectional language workbench. In this talk I will very briefly show mbeddr and recap the 'mbeddr experience'. In particular, I will point out the problems we had to fight with during mbeddr's construction, including those created by MPS as well as those that resulted from our own ignorance. I will close the talk by indentifying some of the areas in which MPS could be (or is currently being) improved: some of them are certainly interesting topics for academic research.Roberto Ierusalimschy: Integers in Lua
Numerical support in programming languages is not a very glamorous subject. Nevertheless, it is a fundamental aspect of any language, and things are far from settled. Each new programming language comes with an almost unique set of number representations and sizes, coercion rules, overflow handling, etc. Lua, unlike most other programming languages, offered only one numerical representation, (double-precision) floating-point numbers. This approach simplifies the language and also its implementation, and for many years served the needs of the language. However, in recent years, two trends changed that situation. One is the spread of 64-bit machines, and with it the spread of 64-bit APIs, algorithms, etc. The other is the increased embedding of Lua in small devices and its use in the "Internet of Things". As a result, after much deliberation, Lua 5.3 (released Jan 2015) has incorporated (64-bit) integers. In this talk, I will discuss the process that led to this change.Matthew Flatt: Binding as Sets of Scopes
Hygienic macro expansion is usually described as a kind of translation into lexical-scope machinery. In particular, variables must be "renamed" to match the mechanisms of lexical scope as the variables interact with macros. In a new macro expander for Racket, we discard the renaming approach and start with a generalized idea of "macro scope", where lexical scope is just a special case of macro scope when applied to a language without macros. The resulting macro system has slightly different properties than the old one, but purely pattern-based macros work as before, and the vast majority of macros in existing Racket code also continue to work. At the same time, the macro system is easier to explain and specify than one based on renaming. The corresponding implementation is simpler, and it avoids bugs that have proven too difficult to repair in the current macro expander.Yannis Smaragdakis: Streams a la Carte: Extensible Pipelines with Object Algebras
Streaming libraries have become ubiquitous in object-oriented languages, with recent offerings in Java, C#, and Scala. All such libraries, however, suffer in terms of extensibility: there is no way to change the semantics of a streaming pipeline (e.g., to fuse filter operators, to perform computations lazily, to log operations) without changes to the library code. Furthermore, in some languages it is not even possible to add new operators (e.g., a zip operator, in addition to the standard map, filter, etc.) without changing the library. We address such extensibility shortcomings with a new design for streaming libraries, based on treating the library as a domain-specific language interpreter. The architecture underlying this design borrows heavily from Oliveira and Cooks object algebra solution to the expression problem, extended with a design that exposes the push/pull character of the iteration, and an encoding of higher-kinded polymorphism. We apply our design to Java and show that the addition of full extensibility is accompanied by high performance, matching or exceeding that of the original, highly-optimized Java streams library.Jonathan Aldrich: On the Evaluation of Language Designs
How does one evaluate a language design? Clearly there are multiple modalities, including case studies, human subjects experiments, benchmarking, code corpus studies, observational studies, etc. What are the strengths and drawbacks of each? Are there examples of each in the literature that we find exemplary? I will lead a structured discussion aimed at coming to a preliminary consensus on some principles at the meeting, and identifying a subgroup interested in turning the results into a paper. Because I am interested in starting an ongoing discussion, I would be interested in giving my talk relatively early in the week. For example, I will be prepared to give it the first day, if scheduling permits.Tuesday
Andrew Tolmach: A Theory of Name Resolution
Joint work with Pierre Neron, Eelco Visser and Guido Wachsmuth We describe a language-independent theory for name binding and resolution, suitable for programming languages with complex scoping rules including both lexical scoping and modules. We formulate name resolution as a two stage problem. First a language-independent scope graph is constructed using language-specific rules from an abstract syntax tree. Then references in the scope graph are resolved to corresponding declarations using a language-independent resolution process. We introduce a resolution calculus as a concise, declarative, and language-independent specification of name resolution. We develop a resolution algorithm that is sound and complete with respect to the calculus. Based on the resolution calculus we develop language-independent definitions of alpha-equivalence and rename refactoring.Klaus Ostermann: Language Design by Duality: Making defunctionalization and refunctionalization symmetric
Reynold's defunctionalization and Danvy's refunctionalization establish a correspondence between programming with first-class functions and programming with pattern matching, but the correspondence is not symmetric: Not all uses of pattern matching can be automatically refunctionalized to uses of higher-order functions. This asymmetry makes it hard to compare the two styles of programming or convert automatically between them. We generalize from first-class functions to arbitrary codata. This leads us to a pair of languages, one with codata support based on Abel's copattern matching and one with data support based on pattern matching. They support full defunctionalization and refunctionalization.Panagiotis Rondogiannis: Extensional Higher-Order Logic Programing
We present a purely extensional higher-order logic programming language. In this language predicates denote sets, and two predicates are equal iff they are equal as sets. Moreover, every program has a unique minimum Herbrand model which is the greatest lower bound of all Herbrand models of the program and the least fixed-point of an immediate consequence operator. In other words, we provide a purely extensional theoretical framework for higher-order logic programming which generalizes the familiar theory of classical (first-order) logic programming. We discuss an extension of the language which supports negation-as-failure, and present its semantics.Francisco Sant'anna: Structured Synchronous Reactive Programming with Céu
Structured synchronous reactive programming (SSRP) augments classical structured programming (SP) with continuous interaction with the environment. We advocate SSRP as viable in multiple domains of reactive applications and propose a new abstraction mechanism for the synchronous language Céu: Organisms extend objects with an execution body that composes multiple lines of execution to react to the environment independently. Compositions bring structured reasoning to concurrency and can better describe state machines typical of reactive applications. Organisms are subject to lexical scope and automatic memory management similar to stack-based allocation for local variables in SP. We show that this model does not require garbage collection or a "free" primitive in the language, eliminating memory leaks for organisms by design.Sam-Tobin Hochstadt: Pycket, a tracing JIT compiler for a functional language.
James Cheney: Teaching (about) PL Design (Discussion)
My department's previous courses on functional programming and operational semantics saw dwindling participation recently, leaving an unsightly gap between the FP and OOP basics covered in the first two years and the advanced courses taught in the fourth year. I am currently facing the challenge (and opportunity) of developing a new PL course aimed at 3rd year students, to fill this gap. Following internal discussion, my current plan is to make language design considerations ("good", "bad", tradeoffs) a unifying theme of the course, and placing greater weight on practical experience (interpreters, DSL implementation) and less on foundations (operational semantics, specification, etc.) than our previous courses. My totally selfish goal in this talk/discussion is to present the context motivating my current plan and provoke the audience into helping me refine and improve it; less selfishly I hope this will also lead to some transferable insights or ideas about how to make PL ideas (including the notion of, and evaluation/appreciation of PL designs, not just isolated features or "paradigms") a central selling point of a flagship PL course. If not, then at least it will be an amusing exercise for the other WGLD participants to poke holes in my current plan.Wednesday
Edwin Brady: Uniqueness Types in Idris
I will present a newly implemented feature in the Idris programming language, Uniqueness Types, and show how they can be used in practice to implement programs with compile time guarantees on resource usage. They are inspired by a similar feature in the Clean programming language, and by Ownership Types in Rust. A value with a uniqueness type can be used at most once in a program. This means that once used, the memory they occupy can be safely reallocated. Furthermore, it becomes possible to represent and reason about state machines directly in types. I will discuss some of the trade-offs in the design and present a practical example, namely type-safe concurrent programming.Roly Perera: Demand-indexed computation
I'll talk about an idea that came out of the work on program slicing that I did for my PhD?. An important role of GUIs is to provide control over the demand active on the output of a computation, via widgets like scrollpanes, collapsible lists, and tooltips. This usually means computing all the output upfront and then hiding some of it, or computing it as needed using ad hoc, application-specific logic. A somewhat independent observation is that pattern-matching imposes a demand on the thing being pattern-matched: for example a function defined by a set of equations needs to know something (but typically not everything) about the argument in order to decide which of its defining equations is applicable. "Tries" (a.k.a. prefix trees), extended with a notion of variable binding, can be used to formalise both of these notions of demand. I'll outline an operational semantics for a simple functional language where the demand on the output is specified explicitly in the form of a trie of a suitable type. Running the same program with more demand produces correspondingly more output. I plan to extend this with a notion of "differential" trie, representing a change in demand, plus a differential operational semantics which, given an increase in demand, does just enough extra work to produce the required extra output. Although I haven't worked this bit out yet, I'll try to explain the idea with several examples.Kostis Sagonas: Type Inference based on Success Typings for Erlang: A Success?
Erlang is a concurrent functional programming language designed by Ericsson to meet the needs of developing large-scale telecommunication systems. It has been designed as a dynamically typed but type safe language. For more than ten years now, Erlang is coming with static analysis tools that perform aggressive type inference based on success typings and a language for optional type declarations and function specifications. In this talk we will try to discuss whether this approach to adding types to a language designed to be dynamically typed was a good or a bad one and the lessons that have been learned in the process.Excursion to Acropolis
After lunch we leave for an afternoon at the AcropolisThursday
Gilad Bracha: Implementing Access Control In Newspeak
(joint work with Ryan Macnak) There is a natural affinity between object-based encapsulation and capability-based security. The Newspeak programming language capitalizes on this affinity. However, until recently Newspeak did not enforce access control. This is changing, and provides a clean basis for building a secure, object-capability based system. Ill discuss the Newspeak access control semantics and our ongoing experience in implementing and using them.Sophia Drossopoulou: Pony
The language Pony was developed with the aim to support easy concurrent programming, fast implementations, and data-race freedom. In terms of case studies and benchmarks, we argue that indeed, Pony programs are fast. In terms of our and our collaborators programming experience, we argue that Pony is easy to learn and program in. We then outline some salient features of the Pony type system, and the garbage collection system.Ross Tate: Collaborating with Ceylon and Kotlin
I have been collaborating with the Ceylon team at Red Hat and the Kotlin team at JetBrains? for approximately 4 years now. In these collaborations, I have not designed any languages; rather I have helped these teams make their designs have the properties that they want. In this process, I have come to understand their underlying design philosophies, many of which are motivated by their development experiences as well as what they perceive to be necessary for industry adoption. I will present my personal understanding of their perspectives, while focusing on aspects that may generalize to other industry language designs. Whether those aspects actually generalize will hopefully prompt lively discussion.Tijs van der Storm: Demo
Crista Lopes: Big Code: What we can learn and What we can do
I will give an account of my 9-year work on mining large repositories of code towards the goal of producing the ultimate "do what I mean" programming environment. I will cover the lessons learned, both positive and not-so-positive. These lessons raise some interesting questions for programming language design.Business Meeting
For membersFriday
Eelco Visser: Dynamic Semantics Specification in DynSem
In this talk I demonstrate the design of the DynSem language for the specification of dynamic semantics. From DynSem specifications we generate interpreter implementations in Java, which are integrated in the IDE for the object language generated by the Spoofax Language Workbench.James Noble: Swapsies on the Internet - First Steps towards Reasoning about Risk and Trust in an Open World
Contemporary open systems use components developed by many different parties, linked together dynamically in unforeseen constellations. Code needs to live up to strict security specifications: it has to ensure the correct functioning of its objects when they collaborate with external objects of unknown provenance, and it has to protect its objects integrity even when external objects are malicious. In this talk we propose specification concepts to model risk and trust in such open systems. We use these concepts to specify the escrow exchange example, and discuss the meaning of such a specification. We'll argue informally that the code satisfies its specificationStefan Hanenberg: Discussion on Empirical Methods
"How do different empirical methods interact? And why do I (still) vote for ignoring qualitative research?" Attachment  | Action | Size | Date | Who | Comment |
|---|---|---|---|---|---|
| | manage | 289.2 K | 08 Nov 2014 - 13:05 | EelcoVisser |
{kind=link}
Revision: r1.15 - 21 Apr 2015 - 08:27 - EelcoVisser